随着大数据技术的快速发展,企业面临着海量数据的高效存储、处理和分析需求。HBase和Spark作为开源大数据生态系统中的关键组件,凭借其高可扩展性、高性能和实时处理能力,成为构建企业级数据处理平台的理想选择。本文结合个人实践经验,探讨如何利用HBase和Spark构建稳定、高效的数据处理服务。
一、HBase与Spark的核心优势
HBase是一个分布式的、面向列的NoSQL数据库,基于Hadoop的HDFS构建,擅长海量数据的随机读写和实时查询。其特点包括:
- 高可扩展性:支持线性水平扩展,可轻松应对PB级数据存储。
- 强一致性:通过HDFS的多副本机制确保数据的可靠性。
- 灵活的数据模型:支持动态列和稀疏表结构,适用于半结构化数据。
Spark则是一个快速、通用的分布式计算引擎,其内存计算能力显著提升了数据处理效率。主要优势包括:
- 高性能:基于内存计算,比传统MapReduce快数十倍。
- 多范式支持:提供批处理、流处理、机器学习和图计算等多种计算模式。
- 易用性:支持Java、Scala、Python等多种语言,API丰富且易于开发。
二、构建企业级数据处理平台的架构设计
一个典型的数据处理平台通常包括数据采集、存储、计算和应用层:
- 数据采集层:通过Kafka、Flume等工具收集来自业务系统、日志和物联网设备的数据。
- 数据存储层:使用HBase作为核心存储,支持实时数据写入和高并发查询。
- 数据处理层:利用Spark进行数据清洗、转换、聚合和分析,结合Spark Streaming实现实时处理。
- 数据服务层:通过REST API或Thrift接口向外提供数据查询和分析结果。
三、关键技术实现与优化
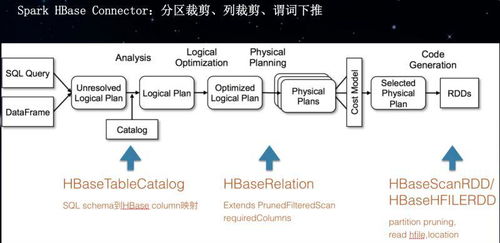
- HBase与Spark的集成:通过Spark的HBase Connector(如HBase-Spark、Hortonworks的SHC)实现高效数据读写,避免数据迁移开销。
- 数据分区与索引优化:根据业务需求设计HBase的RowKey,结合预分区和二级索引提升查询性能。
- 资源管理与调度:利用YARN或Kubernetes对Spark作业进行资源分配和动态调度,确保平台稳定性。
- 监控与告警:集成Prometheus、Grafana等工具,实时监控HBase集群状态和Spark作业运行情况。
四、实际应用场景
- 实时推荐系统:利用HBase存储用户行为数据,Spark MLlib进行实时模型推理,实现个性化推荐。
- 日志分析平台:收集服务器日志存入HBase,通过Spark Streaming进行实时异常检测和趋势分析。
- 物联网数据处理:存储传感器数据至HBase,使用Spark进行批量数据清洗和设备状态预测。
五、挑战与最佳实践
- 数据一致性:通过HBase的原子操作和Spark的Exactly-Once语义保障数据处理的一致性。
- 性能调优:根据数据特征调整HBase的BlockCache、MemStore参数,优化Spark的并行度和内存配置。
- 成本控制:采用冷热数据分离策略,将历史数据归档至低成本存储(如HDFS),降低运营成本。
HBase和Spark的强强联合为企业构建高性能、可扩展的数据处理平台提供了强大支撑。通过合理的架构设计和持续的优化,企业能够充分挖掘数据价值,驱动业务创新与增长。随着技术的演进,未来可进一步探索与AI、云原生技术的深度融合,提升平台的智能化水平和弹性能力。









